前言
久闻 transformer 大名却一直没有完整使用过,这次将利用 transformer 完整地完成一次机翻的任务。
加载项目所需的 package
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import os import json import torch from tokenizers import Tokenizer from tqdm import tqdm from torchtext.vocab import build_vocab_from_iterator import jieba from torch.nn.functional import pad from torch.utils.data import Dataset, DataLoaderfrom torch import nn import mathimport numpy as np import matplotlib.pyplot as plt from torch.utils.tensorboard import SummaryWriter from torch.cuda.amp import autocastfrom torch.cuda.amp import GradScaler
数据集观察
本项目采用的是大规模中文自然语言处理语料项目中的translation2019zh作为训练及测试语料(地址:https://github.com/brightmart/nlp_chinese_corpus)。
1 2 train_data_path = "./corpus/translation2019zh_train.json" valid_data_path = "./corpus/translation2019zh_valid.json"
1 2 3 4 5 train_size = os.path.getsize(train_data_path) valid_size = os.path.getsize(valid_data_path) print (f"train_size: {train_size / (1024 * 1024 * 1024 ):.3 f} GB" )print (f"valid_size: {valid_size / (1024 * 1024 ):.3 f} MB" )
train_size: 1.204 GB
valid_size: 9.380 MB
1 2 3 4 5 6 with open (valid_data_path, "r" , encoding="utf8" ) as f: for line in f: data = json.loads(line) print (data) break
{'english': 'Slowly and not without struggle, America began to listen.', 'chinese': '美国缓慢地开始倾听,但并非没有艰难曲折。'}
1 2 print ("english:" , data["english" ])print ("chinese:" , data["chinese" ])
english: Slowly and not without struggle, America began to listen.
chinese: 美国缓慢地开始倾听,但并非没有艰难曲折。
1 2 3 4 5 6 7 with open (train_data_path, "r" , encoding="utf8" ) as f: cnt1 = len (f.readlines()) with open (valid_data_path, "r" , encoding="utf8" ) as f: cnt2 = len (f.readlines()) print (f"train data len: {cnt1} , valid data len: {cnt2} " )
train data len: 5161434, valid data len: 39323
1 cnt1 = 5161434 ; cnt2 = 39323
1 2 3 4 5 6 7 8 en, ch = 0 , 0 with open (train_data_path, "r" , encoding="utf8" ) as f: for line in f: data = json.loads(line) en = max (en, len (data["english" ].split(" " ))) ch = max (ch, len (data["chinese" ])) print (f"en max: {en} , ch max: {ch} " )
en max: 89, ch max: 200
Summary:
该中英翻译语料库以json格式存储,包含train及vlid两个数据集
数据集中每个句子对以字典形式保存,可通过 english 与 chinese 两个 key 来访问
train数据集包含 500w 条句子对,valid包含 4w 条。
英文句子最大长度大致为 90,中文最大为 200(但具体的token数量取决于tokenize方式)
分词与词典构造
英文词典构造
这里直接使用 bert 的tokenize方法(subword)对英文句子进行分词
1 2 3 4 5 6 7 8 9 10 11 12 tokenizer = Tokenizer.from_pretrained("bert-base-uncased" ) def en_tokenizer (line ): """ 定义英文分词器,后续也要使用 :param line: 一句英文句子,例如"I'm learning Deep learning." :return: subword分词后的记过,例如:['i', "'", 'm', 'learning', 'deep', 'learning', '.'] """ return tokenizer.encode(line, add_special_tokens=False ).tokens
1 2 3 4 5 6 7 8 9 10 11 def yield_en_tokens (filepath ): """ 每次yield一个分词后的英文句子,之所以yield方式是为了节省内存。 如果先分好词再构造词典,那么将会有大量文本驻留内存,造成内存溢出。 """ file = open (filepath, encoding='utf-8' ) print ("-------开始构建英文词典-----------" ) for line in tqdm(file, desc="构建英文词典" , total=cnt1): line = json.loads(line)["english" ] yield en_tokenizer(line) file.close()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 en_vocab_file = "./vocab/vocab_en.pt" en_vocab = build_vocab_from_iterator( yield_en_tokens(train_data_path), min_freq=2 , specials=["<s>" , "</s>" , "<pad>" , "<unk>" ], ) en_vocab.set_default_index(en_vocab["<unk>" ]) torch.save(en_vocab, en_vocab_file)
-------开始构建英文词典-----------
构建英文词典: 100%|██████████| 5161434/5161434 [04:52<00:00, 17643.67it/s]
27867
中文词典构造
这里尝试两种不同的分词方式
1. jieba分词
1 2 3 print ("ch:" , data["chinese" ])print ("jieba: " , jieba.lcut(data["chinese" ]))
ch: 美国缓慢地开始倾听,但并非没有艰难曲折。
jieba: ['美国', '缓慢', '地', '开始', '倾听', ',', '但', '并非', '没有', '艰难曲折', '。']
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def zh_tokenizer (line ): """ 定义中文分词器 :param line: 中文句子,例如:机器学习 :return: 分词结果,例如['机','器','学','习'] """ return jieba.lcut(line) def yield_zh_tokens (filepath ): file = open (filepath, encoding='utf-8' ) for line in tqdm(file, desc="bulid vocab_zh ..." , total=39323 ): line = json.loads(line)["chinese" ] yield zh_tokenizer(line) file.close()
1 2 3 4 5 6 7 8 9 zh_vocab_file = "./vocab/vocab_zh.pt" zh_vocab = build_vocab_from_iterator( yield_zh_tokens(valid_data_path), min_freq=1 , specials=["<s>" , "</s>" , "<pad>" , "<unk>" ], ) zh_vocab.set_default_index(zh_vocab["<unk>" ])
bulid vocab_zh ...: 100%|██████████| 39323/39323 [00:05<00:00, 7374.82it/s]
84346
jieba 分词后词典太大,仅valid就有 8w 个词,不方便后续的操作。
2. 按字分词
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def zh_tokenizer (line ): """ 定义中文分词器 :param line: 中文句子,例如:机器学习 :return: 分词结果,例如['机','器','学','习'] """ return list (line.strip().replace(" " , "" )) def yield_zh_tokens (filepath ): file = open (filepath, encoding='utf-8' ) for line in tqdm(file, desc="bulid vocab_zh ..." , total=39323 ): line = json.loads(line)["chinese" ] yield zh_tokenizer(line) file.close()
1 2 3 4 5 6 7 8 9 10 zh_vocab_file = "./vocab/vocab_zh.pt" zh_vocab = build_vocab_from_iterator( yield_zh_tokens(valid_data_path), min_freq=1 , specials=["<s>" , "</s>" , "<pad>" , "<unk>" ], ) zh_vocab.set_default_index(zh_vocab["<unk>" ])
bulid vocab_zh ...: 100%|██████████| 39323/39323 [00:00<00:00, 89238.05it/s]
5208
直接按字进行分词词典大小就小了很多,降到了 5k
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def zh_tokenizer (line ): """ 定义中文分词器 :param line: 中文句子,例如:机器学习 :return: 分词结果,例如['机','器','学','习'] """ return list (line.strip().replace(" " , "" )) def yield_zh_tokens (filepath ): file = open (filepath, encoding='utf-8' ) for line in tqdm(file, desc="bulid vocab_zh ..." , total=5161434 ): line = json.loads(line)["chinese" ] yield zh_tokenizer(line) file.close()
1 2 3 4 5 6 7 8 9 10 zh_vocab_file = "./vocab/vocab_zh.pt" zh_vocab = build_vocab_from_iterator( yield_zh_tokens(train_data_path), min_freq=1 , specials=["<s>" , "</s>" , "<pad>" , "<unk>" ], ) zh_vocab.set_default_index(zh_vocab["<unk>" ]) torch.save(zh_vocab, zh_vocab_file)
bulid vocab_zh ...: 100%|██████████| 5161434/5161434 [00:34<00:00, 151261.38it/s]
1 2 vocab = torch.load(open ("./vocab/vocab_zh.pt" , "rb" )) vocab.__len__()
10738
对 train 进行分词后的结果也仅为 1w 多。
Summary
我们分别采用 subword 及直接将每个字作为 token 的方式分别对英文及中文进行了分词
观察构建出的词典
1 2 en_vocab = torch.load(open ("./vocab/vocab_en.pt" , "rb" )) zh_vocab = torch.load(open ("./vocab/vocab_zh.pt" , "rb" ))
1 print (f"en_vocab: {len (en_vocab)} , zh_vocab: {len (zh_vocab)} " )
en_vocab: 27867, zh_vocab: 10738
vocab.get_itos() 方法用于返回字典中词的列表
1 en_vocab.get_itos()[:10 ]
['<s>', '</s>', '<pad>', '<unk>', 'the', '.', ',', 'of', 'and', 'to']
1 zh_vocab.get_itos()[:10 ]
['<s>', '</s>', '<pad>', '<unk>', '的', ',', '。', '一', '在', '是']
数据处理
1. 将句子变为 token
1 2 3 4 5 6 7 8 9 10 11 12 13 14 lang2key = {"english" : "en" , "chinese" : "zh" } def sentence2token (file, tokenizer, vocab, lang ): tokens_list = [] filepath = f"./tokens/tokens_{lang2key[lang]} .pt" with open (file, encoding="utf8" ) as f: for line in tqdm(f, desc="building ..." , total=cnt1): line = json.loads(line)[lang] tokens = tokenizer(line) tokens = vocab(tokens) tokens_list.append(tokens) torch.save(tokens_list, filepath)
1 sentence2token(train_data_path, en_tokenizer, en_vocab, "english" )
building ...: 100%|██████████| 5161434/5161434 [08:01<00:00, 10717.05it/s]
1 sentence2token(train_data_path, zh_tokenizer, zh_vocab, "chinese" )
building ...: 100%|██████████| 5161434/5161434 [00:43<00:00, 118331.23it/s]
2. 查看 tokenize 后的数据
1 2 tokens_en = torch.load(open ("./tokens/tokens_en.pt" , "rb" )) tokens_zh = torch.load(open ("./tokens/tokens_zh.pt" , "rb" ))
1 2 3 print (f"tokens_en: {len (tokens_en)} tokens_zh: {len (tokens_zh)} " )print (f"len_tokens_en 0: {len (tokens_en[0 ])} tokens_en 0: {tokens_en[0 ]} " )print (f"len_tokens_zh 0: {len (tokens_zh[0 ])} tokens_zh 0: {tokens_zh[0 ]} " )
tokens_en: 5161434 tokens_zh: 5161434
len_tokens_en 0: 27 tokens_en 0: [15, 1690, 3241, 286, 6, 40, 17, 11, 6539, 541, 10, 2289, 4033, 6, 25, 34, 111, 11, 135, 41, 135, 3408, 6843, 7, 26, 5217, 5]
len_tokens_zh 0: 38 tokens_zh 0: [20, 10, 180, 144, 4, 2185, 96, 5, 133, 9, 889, 343, 4, 37, 54, 7, 78, 1386, 1030, 96, 5, 29, 24, 125, 21, 17, 15, 329, 242, 633, 4, 49, 86, 49, 1742, 828, 703, 6]
1 2 max_len_en = max ([len (t) for t in tokens_en]) max_len_zh = max ([len (t) for t in tokens_zh])
1 print (f"max_len_en: {max_len_en} , max_len_zh: {max_len_zh} " )
max_len_en: 136, max_len_zh: 196
可以看出 token 完之后的最大长度没有超过 200,可据此设定我们的 max_length 大小
查看 token 后的句子能否还原
1 2 3 4 5 with open (train_data_path, encoding="utf8" ) as f: for line in f: cur = json.loads(line) break cur
{'english': 'For greater sharpness, but with a slight increase in graininess, you can use a 1:1 dilution of this developer.',
'chinese': '为了更好的锐度,但是附带的会多一些颗粒度,可以使用这个显影剂的1:1稀释液。'}
vocab.lookup_tokens(list) 用于将索引列表转化为映射后的词列表
1 2 3 print (f"corpus:" , cur["chinese" ])print (f"tokens: {tokens_zh[0 ]} " )print (f"sentence: {zh_vocab.lookup_tokens(tokens_zh[0 ])} " )
corpus: 为了更好的锐度,但是附带的会多一些颗粒度,可以使用这个显影剂的1:1稀释液。
tokens: [20, 10, 180, 144, 4, 2185, 96, 5, 133, 9, 889, 343, 4, 37, 54, 7, 78, 1386, 1030, 96, 5, 29, 24, 125, 21, 17, 15, 329, 242, 633, 4, 49, 86, 49, 1742, 828, 703, 6]
sentence: ['为', '了', '更', '好', '的', '锐', '度', ',', '但', '是', '附', '带', '的', '会', '多', '一', '些', '颗', '粒', '度', ',', '可', '以', '使', '用', '这', '个', '显', '影', '剂', '的', '1', ':', '1', '稀', '释', '液', '。']
可以准确还原
3. 将 tokens 长度统一以形成 batch
pad 函数的作用
Args:
input (Tensor): N-dimensional tensor
pad (tuple): m-elements tuple, where m 2 ≤ i n p u t d i m e n s i o n s \frac{m}{2} \leq input\ dimensions 2 m ≤ in p u t d im e n s i o n s m m m
mode: 'constant', 'reflect', 'replicate' or 'circular'.'constant'
value: fill value for 'constant' padding. Default: 0
1 2 3 4 5 6 from torch.nn.functional import pad x = torch.arange(0 , 10 ) p = (0 , 5 ) x = pad(x, pad=p, value=0 ) x
tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 0, 0, 0, 0])
可以看到 x 的右侧填充了 5 个 0
1 2 3 4 x = torch.arange(0 , 10 ) p = (0 , -2 ) x = pad(x, pad=p, value=0 ) x
tensor([0, 1, 2, 3, 4, 5, 6, 7])
若第二项为负则代表要舍去一些数字,可以看出此处舍去了后两个数字,可利用这种特性来对 tokens 进行 truncate
构建 collate_fn 函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 def collate_fn (batch ): """ 将dataset的数据进一步处理,并组成一个batch。 :param batch: 一个batch的数据,例如: [([6, 8, 93, 12, ..], [62, 891, ...]), .... ...] :return: 填充后的且等长的数据,包括src, tgt, tgt_y, n_tokens 其中src为原句子,即要被翻译的句子 tgt为目标句子:翻译后的句子,但不包含最后一个token tgt_y为label:翻译后的句子,但不包含第一个token,即<bos> n_tokens:tgt_y中的token数,<pad>不计算在内。 """ bs_id = torch.tensor([0 ]) eos_id = torch.tensor([1 ]) pad_id = 2 src_list, tgt_list = [], [] for (_src, _tgt) in batch: """ _src: 英语句子,例如:`I love you`对应的index _tgt: 中文句子,例如:`我 爱 你`对应的index """ processed_src = torch.cat( [bs_id, torch.tensor(_src, dtype=torch.int64), eos_id], 0 ) processed_tgt = torch.cat( [bs_id, torch.tensor(_tgt, dtype=torch.int64), eos_id], 0 ) """ 将长度不足的句子进行填充到max_padding的长度的,然后增添到list中 pad:假设processed_src为[0, 1136, 2468, 1349, 1] 第二个参数为: (0, 72-5) 第三个参数为:2 则pad的意思表示,给processed_src左边填充0个2,右边填充67个2。 最终结果为:[0, 1136, 2468, 1349, 1, 2, 2, 2, ..., 2] """ src_list.append(pad(processed_src, (0 , max_length - len (processed_src)), value=pad_id)) tgt_list.append(pad(processed_tgt, (0 , max_length - len (processed_tgt)), value=pad_id)) src = torch.stack(src_list) tgt = torch.stack(tgt_list) tgt_y = tgt[:, 1 :] tgt = tgt[:, :-1 ] n_tokens = (tgt_y != 2 ).sum () return src, tgt, tgt_y, n_tokens
5. dataset 及 dataloader 的构建
1 2 3 4 5 6 7 8 9 10 11 12 class CorpusSet (Dataset ): def __init__ (self ) -> None : self.en_tokens = torch.load("./tokens/tokens_en.pt" ) self.zh_tokens = torch.load("./tokens/tokens_zh.pt" ) def __getitem__ (self, index ): return self.en_tokens[index], self.zh_tokens[index] def __len__ (self ): return len (self.en_tokens)
1 2 3 4 5 6 7 BATCHSIZE = 64 dataloader = DataLoader( dataset, batch_size=BATCHSIZE, shuffle=True , collate_fn=collate_fn )
查看 dataloader 好不好使
1 2 3 4 5 6 for src, tgt, tgt_y, n_tokens in dataloader: print (f"src_shape: {src.shape} ," ) print (f"tgt_shape: {tgt.shape} ," ) print (f"tgt_y_shape: {tgt_y.shape} " ) print (f"n_tokens: {n_tokens} " ) break
src_shape: torch.Size([64, 200]),
tgt_shape: torch.Size([64, 199]),
tgt_y_shape: torch.Size([64, 199])
n_tokens: 2361
Summary
可以看到 dataloader 顺利地把数据形成了 shape 相同的 batch,并且还自动转成了 tensor 类型(dataset 里面是 list 类型),其中:
src_shape[1] 即为我们设定的 max_len 大小
两个 tgt 的长度均为 max_len - 1,这是由于返回的时候分别去除了 <bos> 与 <eos> 的结果
n_tokens 代表一个 batch 中一共要预测多少个字符
模型构建
此处仅实现 positional encoding 的部分,其余调用 torch.nn.Transformer 接口,transformer 的实现见另一个 project:------------
PE
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 from torch import nn import math class PositionalEncoding (nn.Module): "Implement the PE function." def __init__ (self, d_model, dropout, device, max_len=5000 ): super (PositionalEncoding, self).__init__() self.dropout = nn.Dropout(p=dropout) pe = torch.zeros(max_len, d_model).to(device) position = torch.arange(0 , max_len).unsqueeze(1 ) div_term = torch.exp( torch.arange(0 , d_model, 2 ) * -(math.log(10000.0 ) / d_model) ) pe[:, 0 ::2 ] = torch.sin(position * div_term) pe[:, 1 ::2 ] = torch.cos(position * div_term) pe = pe.unsqueeze(0 ) self.register_buffer("pe" , pe) def forward (self, x ): """ x 为embedding后的inputs,例如(1,7, 128),batch size为1,7个单词,单词维度为128 """ x = x + self.pe[:, : x.size(1 )].requires_grad_(False ) return self.dropout(x)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 class TranslationModel (nn.Module): def __init__ (self, d_model, src_vocab, tgt_vocab, device, dropout=0.1 ): super (TranslationModel, self).__init__() self.device = device self.src_embedding = nn.Embedding(len (src_vocab), d_model, padding_idx=2 ) self.tgt_embedding = nn.Embedding(len (tgt_vocab), d_model, padding_idx=2 ) self.positional_encoding = PositionalEncoding(d_model, dropout, device, max_len=max_length) self.transformer = nn.Transformer(d_model, dim_feedforward=int (4 * d_model), dropout=dropout, batch_first=True ) self.predictor = nn.Linear(d_model, len (tgt_vocab)) @staticmethod def get_key_padding_mask (tokens ): """ 用于key_padding_mask """ return tokens == 2 def forward (self, src, tgt ): """ 进行前向传递,输出为Decoder的输出。注意,这里并没有使用self.predictor进行预测, 因为训练和推理行为不太一样,所以放在了模型外面。 :param src: 原batch后的句子,例如[[0, 12, 34, .., 1, 2, 2, ...], ...] :param tgt: 目标batch后的句子,例如[[0, 74, 56, .., 1, 2, 2, ...], ...] :return: Transformer的输出,或者说是TransformerDecoder的输出。 """ """ 生成tgt_mask,即阶梯型的mask,例如: [[0., -inf, -inf, -inf, -inf], [0., 0., -inf, -inf, -inf], [0., 0., 0., -inf, -inf], [0., 0., 0., 0., -inf], [0., 0., 0., 0., 0.]] tgt.size()[-1]为目标句子的长度。 """ tgt_mask = nn.Transformer.generate_square_subsequent_mask(tgt.size()[-1 ]).to(self.device) src_key_padding_mask = TranslationModel.get_key_padding_mask(src) tgt_key_padding_mask = TranslationModel.get_key_padding_mask(tgt) src = self.src_embedding(src) tgt = self.tgt_embedding(tgt) src = self.positional_encoding(src) tgt = self.positional_encoding(tgt) out = self.transformer( src, tgt, tgt_mask=tgt_mask, src_key_padding_mask=src_key_padding_mask, tgt_key_padding_mask=tgt_key_padding_mask ) """ 这里直接返回transformer的结果。因为训练和推理时的行为不一样, 所以在该模型外再进行线性层的预测。 """ return out
在nn.Transformer中,mask的-inf表示遮掩,而0表示不遮掩。而key_padding_mask的True表示遮掩,False表示不遮掩。
观察模型
1 2 device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu" ) model = TranslationModel(256 , en_vocab, zh_vocab, device).to(device)
1 2 3 4 5 6 import warningswarnings.filterwarnings("ignore" ) src = src.to(device) tgt = tgt.to(device) model(src, tgt).shape
模型训练
定义损失与优化器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 from torch.nn.functional import log_softmaxclass TranslationLoss (nn.Module): def __init__ (self ): super (TranslationLoss, self).__init__() self.criterion = nn.KLDivLoss(reduction="sum" ) self.padding_idx = 2 def forward (self, x, target ): """ 损失函数的前向传递 :param x: 将Decoder的输出再经过predictor线性层之后的输出。 也就是Linear后、Softmax前的状态 :param target: tgt_y。也就是label,例如[[1, 34, 15, ...], ...] :return: loss """ """ 由于KLDivLoss的input需要对softmax做log,所以使用log_softmax。 等价于:log(softmax(x)) """ x = log_softmax(x, dim=-1 ) """ 构造Label的分布,也就是将[[1, 34, 15, ...]] 转化为: [[[0, 1, 0, ..., 0], [0, ..., 1, ..,0], ...]], ...] """ true_dist = torch.zeros(x.size()).to(device) true_dist.scatter_(1 , target.data.unsqueeze(1 ), 1 ) mask = torch.nonzero(target.data == self.padding_idx) if mask.dim() > 0 : true_dist.index_fill_(0 , mask.squeeze(), 0.0 ) return self.criterion(x, true_dist.clone().detach())
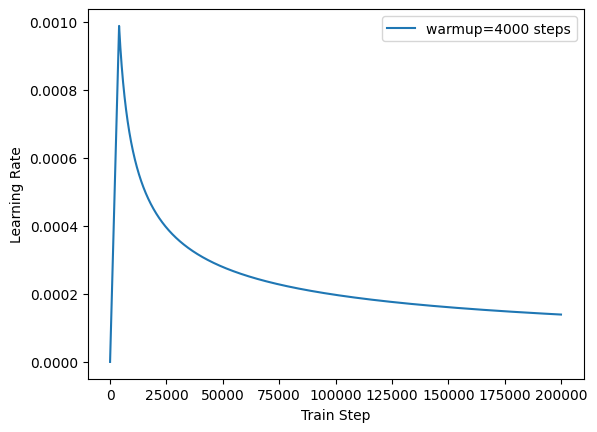
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class CustomSchedule (torch.optim.lr_scheduler._LRScheduler): def __init__ (self, optimizer, d_model, warm_steps=4 ): self.optimizer = optimizer self.d_model = d_model self.warmup_steps = warm_steps super (CustomSchedule, self).__init__(optimizer) def get_lr (self ): """ # rsqrt 函数用于计算 x 元素的平方根的倒数. 即= 1 / sqrt{x} arg1 = torch.rsqrt(torch.tensor(self._step_count, dtype=torch.float32)) arg2 = torch.tensor(self._step_count * (self.warmup_steps ** -1.5), dtype=torch.float32) dynamic_lr = torch.rsqrt(self.d_model) * torch.minimum(arg1, arg2) """ arg1 = self._step_count ** (-0.5 ) arg2 = self._step_count * (self.warmup_steps ** -1.5 ) dynamic_lr = (self.d_model ** (-0.5 )) * min (arg1, arg2) return [dynamic_lr for group in self.optimizer.param_groups]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 optimizer = torch.optim.Adam(model.parameters(), lr=0 , betas=(0.9 , 0.98 ), eps=1e-9 ) learning_rate = CustomSchedule(optimizer, 256 , warm_steps=4000 ) lr_list = [] for i in range (1 , 200000 ): learning_rate.step() lr_list.append(learning_rate.get_lr()[0 ]) plt.figure() plt.plot(np.arange(1 , 200000 ), lr_list) plt.legend(['warmup=4000 steps' ]) plt.ylabel("Learning Rate" ) plt.xlabel("Train Step" ) plt.show()
模型训练
1 torch.cuda.empty_cache()
1 2 3 4 step = 0 model_checkpoint = None epochs = 5 save_after_step = 5000
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 from torch.utils.tensorboard import SummaryWriterfrom torch.cuda.amp import autocastfrom torch.cuda.amp import GradScalerdevice = torch.device("cuda:1" if torch.cuda.is_available() else "cpu" ) model = TranslationModel(256 , en_vocab, zh_vocab, device).to(device) writer = SummaryWriter("./logs/loss" ) criteria = TranslationLoss() optimizer = torch.optim.Adam(model.parameters(), lr=0 , betas=(0.9 , 0.98 ), eps=1e-9 ) learning_rate = CustomSchedule(optimizer, 256 , warm_steps=4000 ) scaler = GradScaler() model.train() for epoch in range (epochs): loop = tqdm(enumerate (dataloader), total=len (dataloader)) for index, data in enumerate (dataloader): src, tgt, tgt_y, n_tokens = data src, tgt, tgt_y = src.to(device), tgt.to(device), tgt_y.to(device) optimizer.zero_grad() with autocast(): out = model(src, tgt) out = model.predictor(out) """ 计算损失。由于训练时我们的是对所有的输出都进行预测,所以需要对out进行reshape一下。 我们的out的Shape为(batch_size, 词数, 词典大小),view之后变为: (batch_size*词数, 词典大小)。 而在这些预测结果中,我们只需要对非<pad>部分进行,所以需要进行正则化。也就是 除以n_tokens。 """ loss = criteria(out.contiguous().view(-1 , out.size(-1 )), tgt_y.contiguous().view(-1 )) / n_tokens scaler.scale(loss).backward() scaler.step(optimizer) scaler.update() learning_rate.step() loop.set_description("Epoch {}/{}" .format (epoch, epochs)) loop.set_postfix(loss=loss.item()) loop.update(1 ) step += 1 writer.add_scalar("step_loss" , loss.item(), step) del src del tgt del tgt_y if step != 0 and step % save_after_step == 0 : torch.save(model, f"./models/model_{step} .pt" ) writer.close()
Epoch 0/5: 100%|██████████| 80648/80648 [5:46:57<00:00, 3.87it/s, loss=2.7]
Epoch 1/5: 100%|██████████| 80648/80648 [5:32:57<00:00, 4.04it/s, loss=2.33]
Epoch 2/5: 100%|██████████| 80648/80648 [6:04:58<00:00, 3.68it/s, loss=2.22]
Epoch 3/5: 100%|██████████| 80648/80648 [6:08:04<00:00, 3.65it/s, loss=2.75]
Epoch 4/5: 100%|██████████| 80648/80648 [5:55:01<00:00, 3.47it/s, loss=2.35]
模型测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 def translate (model, src: str ): """ :param src: 英文句子,例如 "I like machine learning." :return: 翻译后的句子,例如:”我喜欢机器学习“ """ model.eval () src = torch.tensor([0 ] + en_vocab(en_tokenizer(src)) + [1 ]).unsqueeze(0 ).to(device) tgt = torch.tensor([[0 ]]).to(device) for i in range (max_length): out = model(src, tgt) predict = model.predictor(out[:, -1 ]) y = torch.argmax(predict, dim=1 ) tgt = torch.concat([tgt, y.unsqueeze(0 )], dim=1 ) if y == 1 : break tgt = '' .join(zh_vocab.lookup_tokens(tgt.squeeze().tolist())).replace("<s>" , "" ).replace("</s>" , "" ) return tgt
1 2 model = TranslationModel(256 , en_vocab, zh_vocab, device) model = torch.load(open ("./models/model_300000.pt" , "rb" ))
1 2 3 4 5 6 print (translate(model, "hard to say" ))print (translate(model, "time to finish this, vergil, once for all" ))print (translate(model, "if you want it, then you have to take it" ))print (translate(model, "but you already know that" ))print (translate(model, "you shall die!" ))print (translate(model, "I am the storm that is approaching!" ))
难说话。
为了完成这一点,维埃尔,一次是为所有。
如果你想要它,那么你必须要拿它。
但你已经知道了。
你应该死!
我是那是那个正在接近的风暴!
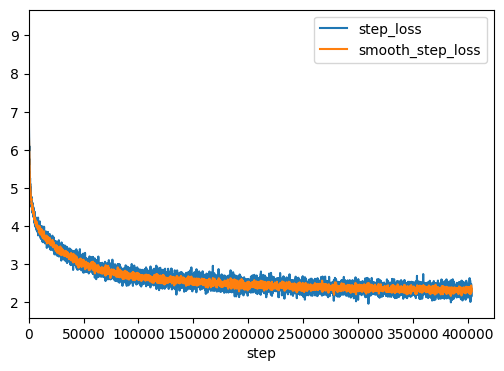
查看日志的loss曲线
1 2 3 4 5 import os for root, ds, fs in os.walk("./logs/loss/" ): for f in fs: path = os.path.join(root, f) print (os.path.getsize(path), path)
415337 ./logs/loss/events.out.tfevents.1680356226.sjtu-Z490-AORUS-PRO-AX.308572.1
19742290 ./logs/loss/events.out.tfevents.1680358604.sjtu-Z490-AORUS-PRO-AX.312696.0
40 ./logs/loss/events.out.tfevents.1680356221.sjtu-Z490-AORUS-PRO-AX.308572.0
1 2 3 4 5 6 7 from tensorboard.backend.event_processing import event_accumulatorpath = "./logs/loss/events.out.tfevents.1680358604.sjtu-Z490-AORUS-PRO-AX.312696.0" ea=event_accumulator.EventAccumulator(path) ea.Reload() print (ea.scalars.Keys())
['step_loss']
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import matplotlib.pyplot as pltfrom scipy import signalfig=plt.figure(figsize=(6 ,4 )) ax1=fig.add_subplot(111 ) s_loss = ea.scalars.Items('step_loss' ) loss = signal.savgol_filter([i.value for i in s_loss], 10 , 3 ) ax1.plot([i.step for i in s_loss], [i.value for i in s_loss], label = "step_loss" ) ax1.plot([i.step for i in s_loss], loss, label='smooth_step_loss' ) ax1.set_xlim(0 ) ax1.set_xlabel("step" ) ax1.set_ylabel("" ) plt.legend(loc='upper right' ) plt.show()
总结
鸽