unsignedchar* data; ///< tile原始数据。会转成可序列化的数据,供序列化函数使用。 int dataSize; ///< tile原始数据长度 int flags; ///< Tile flags. (See: #dtTileFlags) dtMeshTile* next; ///< The next free tile, or the next tile in the spatial grid.
//@UE4 BEGIN #if WITH_NAVMESH_SEGMENT_LINKS dtOffMeshSegmentConnection* offMeshSeg; ///< The tile off-mesh connections. [Size: dtMeshHeader::offMeshSegConCount] #endif// WITH_NAVMESH_SEGMENT_LINKS
#if WITH_NAVMESH_CLUSTER_LINKS dtCluster* clusters; ///< Cluster data unsignedshort* polyClusters; ///< Cluster Id for each ground type polygon [Size: dtMeshHeader::polyCount]
dtChunkArray<dtClusterLink> dynamicLinksC; ///< Dynamic links array (indices starting from DT_CLINK_FIRST) unsignedint dynamicFreeListC; ///< Index of the next free dynamic link #endif// WITH_NAVMESH_CLUSTER_LINKS
dtChunkArray<dtLink> dynamicLinksO; ///< Dynamic links array (indices starting from dtMeshHeader::maxLinkCount) unsignedint dynamicFreeListO; ///< Index of the next free dynamic link //@UE4 END };
/// Defines a polyogn within a dtMeshTile object. /// @ingroup detour structdtPoly { // 指向该节点的第一个链接 /// Index to first link in linked list. (Or #DT_NULL_LINK if there is no link.) unsignedint firstLink;
/// Defines a link between polygons. /// @note This structure is rarely if ever used by the end user. /// @see dtMeshTile structdtLink { dtPolyRef ref; ///< Neighbour reference. (The neighbor that is linked to.) unsignedint next; ///< Index of the next link. unsignedchar edge; ///< Index of the polygon edge that owns this link. unsignedchar side; ///< If a boundary link, defines on which side the link is. unsignedchar bmin; ///< If a boundary link, defines the minimum sub-edge area. unsignedchar bmax; ///< If a boundary link, defines the maximum sub-edge area. };
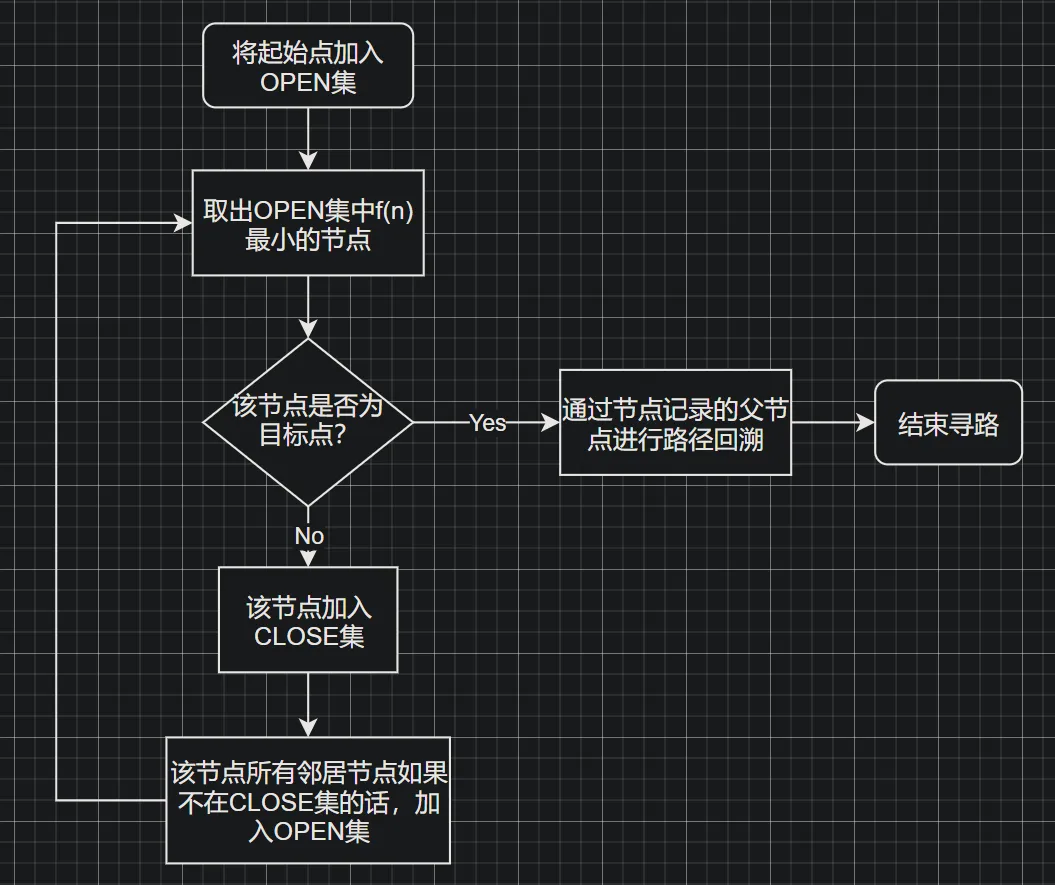
// 遍历当前节点(Poly)的所有邻居 unsignedint i = bestPoly->firstLink; while (i != DT_NULL_LINK) { // 整个循环会单独处理每一个邻居 // 一个link指向当前的一个邻居 const dtLink& link = m_nav->getLink(bestTile, i); i = link.next;
dtPolyRef neighbourRef = link.ref; // Skip invalid ids and do not expand back to where we came from. if (!neighbourRef || neighbourRef == parentRef //@UE4 BEGIN || !filter->isValidLinkSide(link.side)) //@UE4 END continue; // 获取邻居节点的tile和poly数据 const dtMeshTile* neighbourTile = 0; const dtPoly* neighbourPoly = 0; m_nav->getTileAndPolyByRefUnsafe(neighbourRef, &neighbourTile, &neighbourPoly);
// 可以通过自定义的filter,来过滤掉哪些不希望被查询的节点 if (!filter->passFilter(neighbourRef, neighbourTile, neighbourPoly) || !passLinkFilterByRef(neighbourTile, neighbourRef)) continue;
dtNode* neighbourNode = m_nodePool->getNode(neighbourRef); if (!neighbourNode) { status |= DT_OUT_OF_NODES; continue; } //@UE4 BEGIN // 如果不存在负权值,过滤掉对于状态为close的节点 elseif (shouldIgnoreClosedNodes && (neighbourNode->flags & DT_NODE_CLOSED) != 0) { continue; } //@UE4 END
// Try to update node position for current edge to make paths more precise // Unless heuristic is not admissible (overestimates), in which case // we have to use constant values for given node to avoid creating cycles float neiPos[3] = { 0.0f, 0.0f, 0.0f }; // h系数大于1表示距离目标点的距离估算占比更大,更偏向于BFS算法,一般情况运算速度更快。 // h系数小于1表示当前已经历的距离占比更大,更偏向于Dijkstra算法,一般情况更精确。 // 一般来说,h系数越大,表明希望运算速度越快,而精度会越低 if (H_SCALE <= 1.0f || neighbourNode->flags == 0) { // 当h系数小于1时,或者邻居节点并没有被检查过时,表明希望使用更精确的路径,会取到相邻的两个多边形的邻边的中点来代替邻居节点的坐标 // 算法见dtNavMeshQuery::getPortalPoints() getEdgeMidPoint(bestRef, bestPoly, bestTile, neighbourRef, neighbourPoly, neighbourTile, neiPos); } else { dtVcopy(neiPos, neighbourNode->pos); }