
C# 补完计划(一):值类型与引用类型
值类型与引用类型
在C#中值类型的变量直接存储数据,而引用类型的变量持有的是数据的引用,数据存储在数据堆中。
值类型(value type):byte,short,int,long,float,double,decimal,char,bool 和 struct 统称为值类型。值类型变量声明后,不管是否已经赋值,编译器为其分配内存。

引用类型(reference type):string 和 class统称为引用类型。当声明一个类时,只在栈中分配一小片内存用于容纳一个地址,而此时并没有为其分配堆上的内存空间。当使用 new 创建一个类的实例时,分配堆上的空间,并把堆上空间的地址保存到栈上分配的小片空间中。
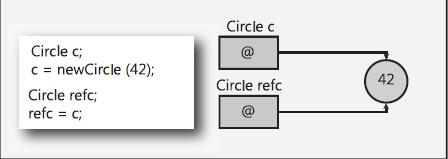
值类型的实例通常是在线程栈上分配的(静态分配),但是在某些情形下可以存储在堆中。引用类型的对象总是在进程堆中分配(动态分配)。
从概念上看,值类型直接存储其值,而引用类型存储对其值的引用。这两种类型存储在内存的不同地方。在C#中,我们必须在设计类型的时候就决定类型实例的行为。这种决定非常重要,用《CLR via C#》作者Jeffrey Richter的话来说,“不理解引用类型和值类型区别的程序员将会给代码引入诡异的bug和性能问题(I believe that a developer who misunderstands the difference between reference types and value types will introduce subtle bugs and performance issues into their code.)”。这就要求我们正确理解和使用值类型和引用类型。
通用类型系统
C#中,变量是值还是引用仅取决于其数据类型。
C#的基本数据类型都以平台无关的方式来定义。C#的预定义类型并没有内置于语言中,而是内置于 .NET Framework中。.NET使用通用类型系统(CTS)定义了可以在中间语言(IL)中使用的预定义数据类型,所有面向 .NET的语言都最终被编译为IL,即编译为基于CTS类型的代码。
例如,在C#中声明一个int变量时,声明的实际上是CTS中System.Int32的一个实例。这具有重要的意义:
-
确保IL上的强制类型安全;
-
实现了不同 .NET语言的互操作性;
-
所有的数据类型都是对象。它们可以有方法,属性,等。例如:
1
2
3
4int i;
i = 1 ;
string s;
s = i.ToString();
MSDN的这张图说明了CTS中各个类型是如何相关的。注意,类型的实例可以只是值类型或自描述类型,即使这些类型有子类别也是如此。
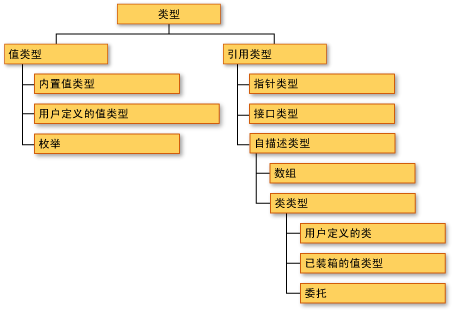
值类型
C#的所有值类型均隐式派生自System.ValueType。
-
结构体:struct(直接派生于
System.ValueType); -
数值类型:
- 整型:
sbyte(System.SByte的别名),short(System.Int16),int(System.Int32),long(System.Int64),byte(System.Byte),ushort(System.UInt16),uint(System.UInt32),ulong(System.UInt64),char(System.Char); - 浮点型:
float(System.Single),double(System.Double); - 用于财务计算的高精度
decimal型:decimal(System.Decimal)。
- 整型:
-
bool型:
bool(System.Boolean的别名); -
用户定义的结构体(派生于
System.ValueType)。 -
枚举:
enum(派生于System.Enum); -
可空类型(派生于
System.Nullable<T>泛型结构体,T?实际上是System.Nullable<T>的别名)。
C# 提供了一个特殊的数据类型,nullable类型(可空类型),可空类型可以表示其基础值类型正常范围内的值,再加上一个null值。例如,
Nullable< Int32 >,读作"可空的 Int32",可以被赋值为-2,147,483,648到2,147,483,647之间的任意值,也可以被赋值为null值。类似的,Nullable< bool >变量可以被赋值为true或false或null。在处理数据库和其他包含可能未赋值的元素的数据类型时,将
null赋值给数值类型或布尔型的功能特别有用。例如,数据库中的布尔型字段可以存储值true或false,或者,该字段也可以未定义。声明一个
nullable类型(可空类型)的语法如下:1
< data_type> ? <variable_name> = null;
每种值类型均有一个隐式的默认构造函数来初始化该类型的默认值。例如:
1 | int i = new int(); // i = 0 |
使用new运算符时,将调用特定类型的默认构造函数并对变量赋以默认值。在上例中,默认构造函数将值0赋给了i。MSDN上有完整的默认值表。
所有的值类型都是密封(seal)的,所以无法派生出新的值类型。
值得注意的是,引用类型和值类型都继承自System.Object类。不同的是,几乎所有的引用类型都直接从System.Object继承,而值类型则继承其子类,即 直接继承System.ValueType。System.ValueType直接派生于System.Object。即System.ValueType本身是一个类类型,而不是值类型。其关键在于 ValueType重写了Equals()方法,从而对值类型按照实例的值来比较,而不是引用地址来比较。
可以用Type.IsValueType属性来判断一个类型是否为值类型。
引用类型
C#有以下一些引用类型:
-
数组(派生于
System.Array) -
用户用定义的以下类型:
-
类:
class(派生于System.Object); -
接口:
interface(接口不是一个“东西”,所以不存在派生于何处的问题。Anders在《C# Programming Language》中说,接口只是表示一种约定[contract]); -
委托:
delegate(派生于System.Delegate)。
-
-
object(System.Object的别名); -
字符串:
string(System.String的别名)。
可以看出:
- 引用类型与值类型相同的是,结构体也可以实现接口;
- 引用类型可以派生出新的类型,而值类型不能;
- 引用类型可以包含
null值,值类型不能(可空类型功能允许将null赋给值类型); - 引用类型变量的赋值只复制对对象的引用,而不复制对象本身。而将一个值类型变量赋给另一个值类型变量时,将复制包含的值。
拆箱与装箱
概念
简单来说,装箱是将值类型转换为引用类型 ;拆箱是将引用类型转换为值类型。
C# 中值类型和引用类型的最终基类都是 Object 类型(它本身是一个引用类型)。也就是说,值类型也可以当做引用类型来处理。而这种机制的底层处理就是通过装箱和拆箱的方式来进行,利用装箱和拆箱功能,可通过允许值类型的任何值与 Object 类型的值相互转换,将值类型与引用类型链接起来 。
例如:
1 | int val = 100; |
这里,val 是一个值类型,obj 是一个引用类型。在这里,val 被装箱为 obj。
1 | int val = 100; |
这里,obj 是一个引用类型,i 是一个值类型。在这里,obj 被拆箱为 i。
被装过箱的对象才能被拆箱。
装箱和拆箱的内部操作
.NET中,数据类型划分为 值类型 和 引用 (不等同于C++的指针) 类型 ,与此对应,内存分配被分成了两种方式,一为栈,二为堆,注意:是托管堆。
值类型只会在栈中分配(大部分情况下)。 引用类型分配内存与托管堆。(托管堆对应于垃圾回收)
- 装箱操作
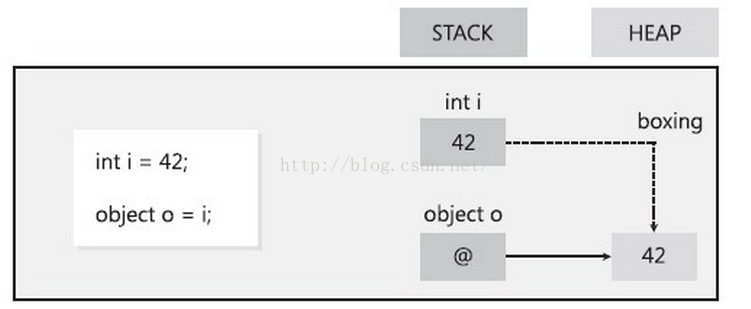
对值类型在堆中分配一个对象实例,并将该值复制到新的对象中。按三步进行。
- 首先从托管堆中为新生成的引用对象分配内存(大小为值类型实例大小加上一个方法表指针和一个
SyncBlockIndex)。 - 然后将值类型的数据拷贝到刚刚分配的内存中。
- 返回托管堆中新分配对象的地址。这个地址就是一个指向对象的引用了。
可以看出,进行一次装箱要进行分配内存和拷贝数据这两项比较影响性能的操作。
- 拆箱操作
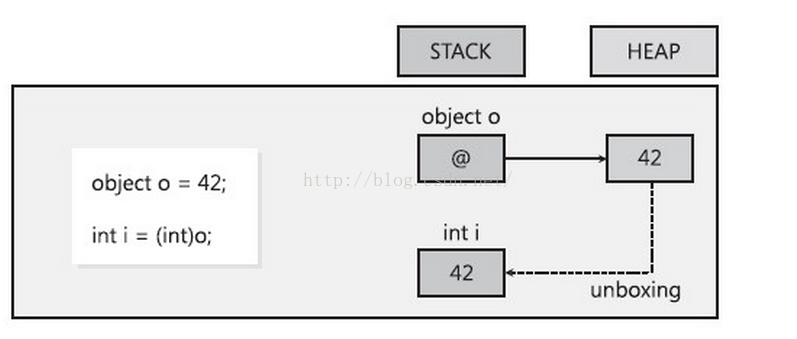
- 首先获取托管堆中属于值类型那部分字段的地址,这一步是严格意义上的拆箱。
- 将引用对象中的值拷贝到位于线程堆栈上的值类型实例中。
经过这2步,可以认为是同boxing是互反操作。严格意义上的拆箱,并不影响性能,但伴随这之后的拷贝数据的操作就会同boxing操作中一样影响性能。
为什么需要装箱(为何要将值类型转为引用类型?)
一种最普通的场景是,调用一个含类型为Object的参数的方法,该Object可支持任意为型,以便通用。当你需要将一个值类型(如Int32)传入时,需要装箱。
另一种用法是,一个非泛型的容器,同样是为了保证通用,而将元素类型定义为Object。于是,要将值类型数据加入容器时,需要装箱。
装箱和拆箱对性能的影响,以及如何避免装箱拆箱
装箱和拆箱都意味着堆和堆栈空间的一系列操作,毫无疑问,这些操作的性能代价是很大的,尤其对于堆上空间的操作,速度相对于堆栈的操作慢的多,并且可能引发垃圾回收,这些都将大规模地影响系统的性能。如何避免装箱拆箱操作,是程序员在编写代码时需要时刻考虑的一个问题。装箱和拆箱操作常发生在以下两个场合:
- 值类型的格式化输出。
System.Object类型的容器。
第一种情况,值类型的格式化输出往往会涉及一次装箱操作。例如下面的两行代码:
1 | int i = 10; |
代码完全能够通过编译并且正确执行,但却引发了一次不必要的装箱操作。在第2行代码上,值类型 i 被作为一个System.Object对象传入方法之中,这样的操作完全可以通过下面的改动来避免:
1 | int i = 10; |
改动后的代码调用了 i 的 ToString() 方法来得到一个字符串对象。由于字符串是引用类型,所以改动后的代码就不在涉及装箱操作。
第二种情况更为常见一些。例如常用的容器类 ArrayList,就是一个典型的 System.Object 容器。任何值类型被放入 ArrayList 的对象中,都会引发一次装箱操作。而对应的,取出值类型对象就会引发一次拆箱操作。在 .NET 1.1之前,这样的操作很难避免,但在 .NET 2.0推出了泛型的概念后,这些问题得到了有效的解决。泛型允许定义针对某个特定类型(包括值类型)的容器,并且有效的避免装箱和拆箱。



