
程序的编译与运行(二):静态链接
参考:
《程序员的自我修养—链接、装载与库》
《深入理解计算机系统》
前言
现代编译器支持以分离编译的方式单独地编译所有的源文件,然后通过链接将所有模块组装成一个完整的应用。这种方式使得我们可以将一个复杂的应用程序分解成更小、更好管理的模块,并且可以独立地对这些模块进行修改和编译。当我们改变其中一个模块时,只需要对修改的模块重新编译,然后重新进行链接,而不必重新编译其它的模块。
静态链接
程序的编译可分为预处理、编译、汇编以及链接这四个主要阶段(见 C++ 编译过程 ),编译器在完成汇编阶段之后,所有的代码源文件已经都翻译成了二进制的目标文件,但是目标文件相互之间仍然是独立的,很多依赖信息还没有解决,包括:
- 对于每个目标文件,它可能会依赖其它目标文件或者库中的符号信息;
- 对于每个目标文件,其在内存中的运行地址信息此时也是不确定的,因此还无法直接加载到程序中运行。
这些问题都将由静态链接解决。静态链接的核心作用就是将编译生成的多个目标文件及其依赖的库进行链接,以生成最终的可执行文件。静态链接的基本示意如下:
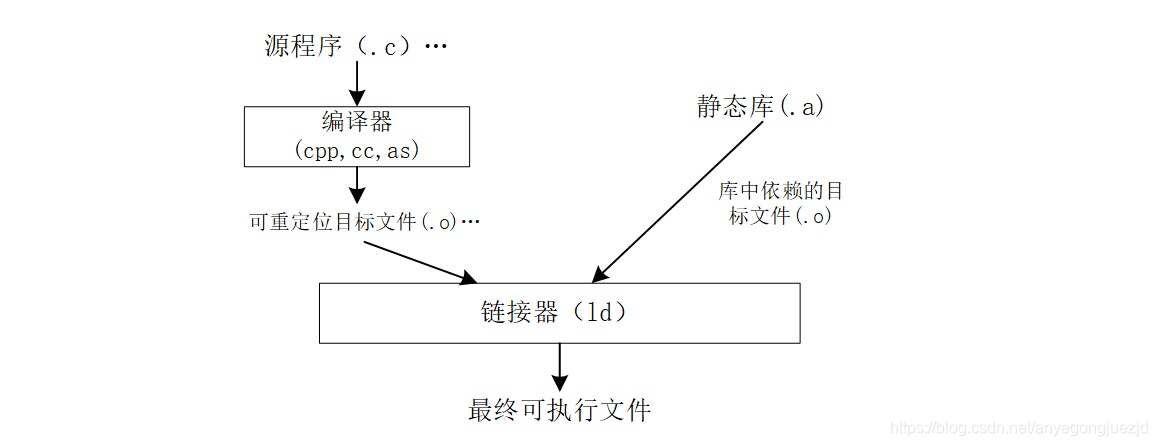
静态链接过程
在 Linux 平台下,使用的静态链接器通常为 ld 工具,为了生成可执行文件,链接器必须完成三个主要任务,概述如下:
-
空间与地址分配:扫描所有输入的目标文件,获取所有文件中节的信息,包括属性、长度和位置等,并且收集所有目标文件中的符号定义和符号引用信息。计算出输出文件中各个段合并后的长度与位置,并建立与目标平台程序地址空间的映射关系;
-
符号解析:目标文件中定义和引用的符号,每个符号都对应于一个函数、全局变量或者静态变量。符号解析的目的就是将每个符号引用和一个符号定义关联起来;
-
重定位:目标文件包含从地址0开始的代码和数据节。链接通过把每个符号定义与一个内存地址关联起来,从而重定位这些节,然后修改所有对这些符号的引用,使得它们指向这个内存位置。
完成这三个任务之后,链接器会为最终的可执行文件指定一个程序入口地址,在链接 C 运行库的情况下,这个入口函数通常为 _start。当可执行文件被加载到内存中时,系统会跳转到指定的入口地址开始执行。
空间与地址分配
现代链接器执行的合并策略比较简单,通过将所有相同类型的节合并到一起,例如将所有输入目标文件的 .text 节合并到输出文件的 .text 节中;然后,链接器根据运行平台中进程虚拟地址空间的划分规则,为所有输入目标文件中定义的节和符号分配运行时内存地址;完成之后,程序中的每条指令和符号都有唯一的运行时内存地址了。链接器的空间分配示意如下:
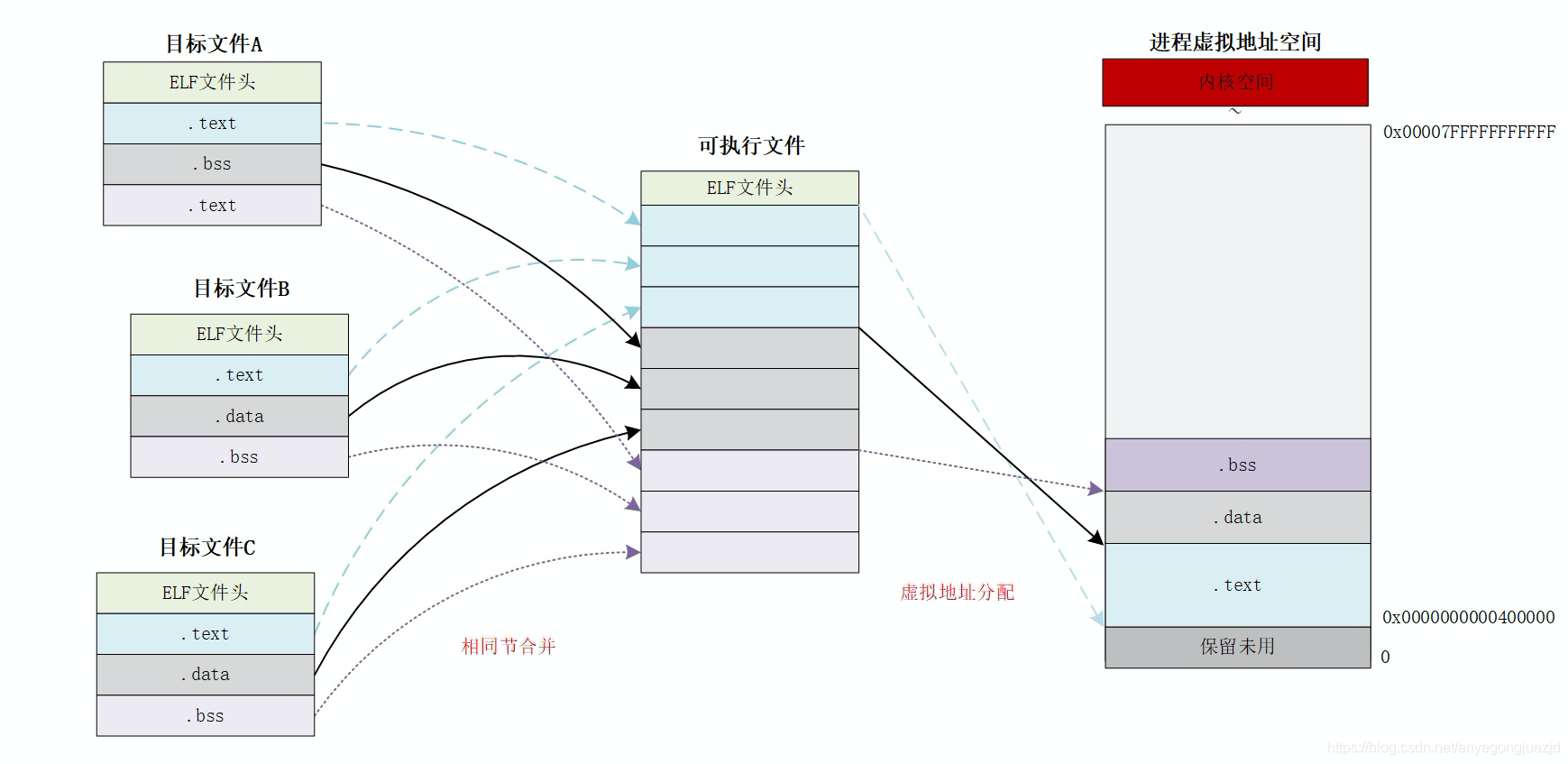
在链接阶段,链接器会为会为所有的目标文件分配地址空间。这里的地址空间需要区分两种含义:
- 可执行文件自身的空间:用于磁盘上静态存储可执行文件的内容;
- 进程虚拟地址空间:由程序运行时,系统加载可执行文件的内容而动态建立。
链接器为可执行文件中符号确定的地址即是最后程序运行时所使用的地址,在可执行文件被装载时会被逐一映射到进程的虚拟地址空间。 典型的装载数据包括代码段和数据段中的数据,一些特殊的段,如.bss段在可执行文件中不占用空间,但是在可执行文件装载后的进程虚拟地址空间中需要进行空间分配。对于其它一些如符号表、调试信息等数据,链接器不会为其分配地址空间,因为它们并不是程序运行所必要的数据,因此也不会被装载入进程虚拟地址空间中去。
空间与地址分配示例
为了说明空间与地址分配的过程,这里使用如下两个源代码文件进行分析,后续也会继续使用这两个文件:
1 | // sum.c |
首先使用 gcc 将 main.c 和 sum.c 编译成目标文件:

经过编译之后,已经生成了两个目标文件main.o和sum.o,在进行链接之前,先看下目标文件中的地址分配情况:
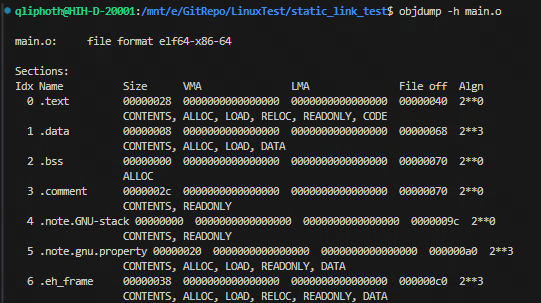
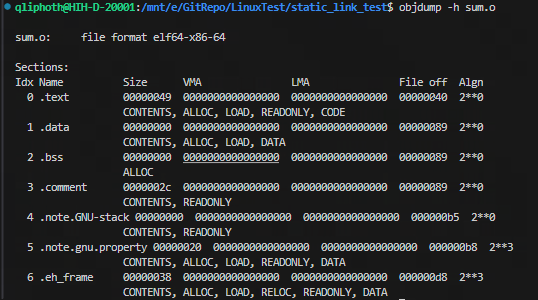
可以看到,生成的每个目标文件都有自己独立的代码段和数据段,并且所有的段都未分配虚拟地址空间,因此文件中所有段的虚拟内存地址(VMA字段)都是 0。如果反汇编目标文件,可以看到每个目标文件的起始地址都是从 0 开始。
现在我们使用ld链接器将main.o和sum.o链接起来生成可执行文件:

-e 选项用于指定 main 函数作为程序入口,ld 链接器默认的程序入口为 _start,定义于 C 运行库中,在此不链接使用 C 库的函数,因此需要单独指定程序入口。
链接后默认生成的可执行文件名为 a.out,可以查看 a.out 的地址分配情况:
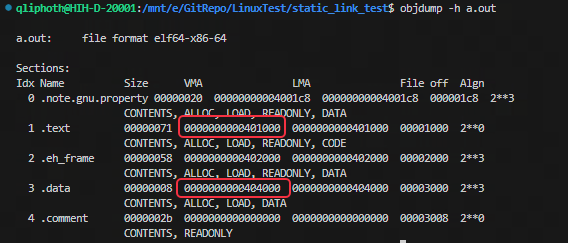
可以看到,在可执行文件中,链接器已经将所有输入目标文件的段进行合并,生成了新的段,并且都分配到了相应的虚拟地址。**当段的起始地址明确之后,段内的指令和数据地址也就逐一确定了。**这里虚拟地址的分配规则对于不同系统的实现是不同的,在32位Linux下,ELF可执行文件默认从地址0x8048000开始;对于64位Linux系统,则默认从0x400000开始。
对于定义的全局符号,由于它们在段内的相对位置都是固定的,链接器只要加上相应的偏移,就可以依次计算出所有的符号的虚拟地址了。对于上面的代码中定义的两个全局符号array和sum,以外部函数sum为例,计算出的虚拟地址值如下:
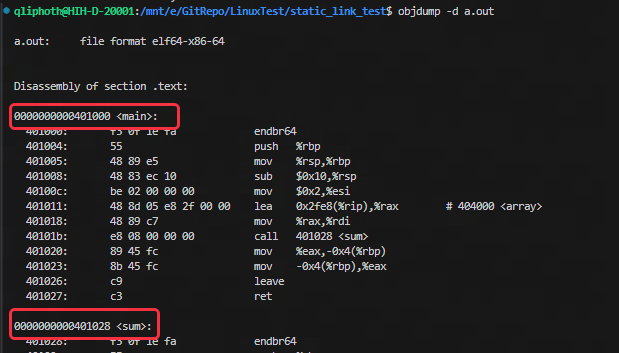
符号解析
在符号解析阶段,链接器根据所有输入的符号引用与定义信息,将程序中每个符号引用与链接过程中输入的可重定位目标文件中的符号表中的一个确定的符号关联起来。如果在链接过程中出现未定义的符号,那么链接过程中就会终止并且报错"undefined reference"。
多重定义的全局符号解析
对于局部符号以及未定义符号的解析,链接器的处理通常是很简单的,更复杂的情况是对全局符号的解析,尤其是当多个目标文件定义了相同的符号。为了能够正确处理这种多重定义的全局符号,编译器在编译时,会将这些符号区分成强符号和弱符号进行输出,这样链接器就可以根据符号的强弱属性,并按照特定的规则进行解析。
对于C/C++语言来说,编译器默认函数和初始化了的全局变量为强符号,未初始化的全局变量为弱符号。注意,强符号和弱符号都是针对定义来说的,不是针对符号的引用。
根据强弱符号的定义,链接器使用下面的规则来处理多重定义的符号:
- 不允许强符号被多次定义,若有多个相同的强符号定义,则链接器报符号重复定义错误;
- 若在输入的目标文件中,定义了一个强符号以及多个同名的弱符号,那么选择强符号;
- 若在所有输入的目标文件中,只定义了多个同名的弱符号,那么选择其中占用空间最大的一个。
GCC扩展支持使用 attribute((weak)) 来定义任何一个强符号为弱符号
1 | int __attribute__((weak)) g_strong_val = 5; // g_strong_val 现在是弱符号 |
特殊符号
在使用 ld 链接器生成可执行文件时,会在链接脚本中定义一些特殊符号,这些符号可以用来对程序链接进行控制,同时也可以在程序中被引用,链接器会在将程序最终链接成可执行文件的时候将其解析成正确的值。一些常见的特殊符号定义如下:
__executable_start:程序起始地址。__etext或_etext或etext:代码段结束地址,即代码段最末尾的地址;_edata或edata:数据段结束地址,及数据段最末尾的地址;_end或end:程序结束地址。
重定位
在完成地址分配和符号解析之后,程序中每个定义的符号都有了唯一的运行时内存地址,并且所有的符号引用都可以与某个确定的符号定义关联起来,然后链接器就可以进入重定位阶段了。在这个阶段中,链接器会读取所有可重定位目标文件中的重定位信息,然后调整代码段和数据段中对每个符号的引用,使它们指向正确的运行时内存地址。
重定位表
重定位信息描述了如何对对应的节区中的符号引用进行修改,ELF 文件使用重定位表来存储重定位信息。对于可重定位文件中每个需要重定位的节区都有一个对应的重定位表(通常使用.rel作为前缀)。表中包含了需要进行重定位的项,典型的重定位表包括.rel.text和.rel.data,其中:
-
.rel.text:描述代码段的重定位信息,用于对.text代码段进行重定位; -
.rel.data:描述数据段的重定位信息,用于对.data数据段进行重定位。
可以使用objdump来查看main.o的重定位表:
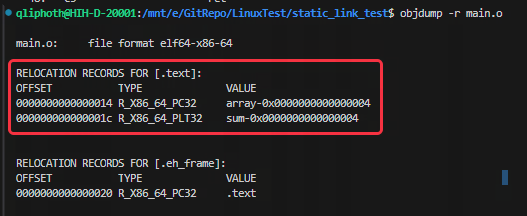
上图中,RELOCATION RECORDS FOR [.text] 表示这个重定位表是代码段的重定位表,后面的信息是需要进行重定位的符号,其中偏移表示代码段中需要被调整的位置。
重定位项
当编译器生成一个可重定位目标文件时,它并不知道代码和数据最终会加载到内存中的什么位置,也不清楚这个模块引用的任何外部定义的符号的位置。因此,当编译器遇到对最终位置未知的符号的引用,就会为其生成一个重定位项,用于指示链接器在链接生成可执行文件时如何修改这个引用。ELF重定位表中存储的重定位项,其结构定义如下:
1 | typedef struct { |
重定位项最主要的作用是记录了需要重定位的符号在文件中的位置以及如何对符号进行重定位。重定位项结构中的各个字段意义如下:
r_offset:用于指明重定位项的地址,对于可重定位文件,字段的值为重定位项相对于所在节的偏移地址;对于可执行文件或共享目标文件,字段的值是链接器为重定位项分配的虚拟地址;r_info:低32位表明了符号重定位的类型,高32位用于确定符号在符号表中的索引;r_addend:附加的符号常数,一些重定位类型要使用这个常数被对被修改引用的值进行偏移调整。
重定位类型
R_X86_64_32:(该类型在新版的GCC上已经没有看到了). 重定位一个使用32位绝对地址的引用。R_X86_64_PC32: 重定位一个使用32位PC相对地址的引用。R_X86_64_PLT32: 过程链接表延迟绑定。
重定位符号引用
在前面示例源码中,main 函数引用了两个全局符号 array 和 sum。编译器为每个引用都生成了一个重定位项,每项的描述信息可以在重定位表中进行查看。这里将main.o 目标文件进行反汇编,可以看到编译器已经指定需要为下图中两个位置的对 array 和 sum 的引用进行重定位:
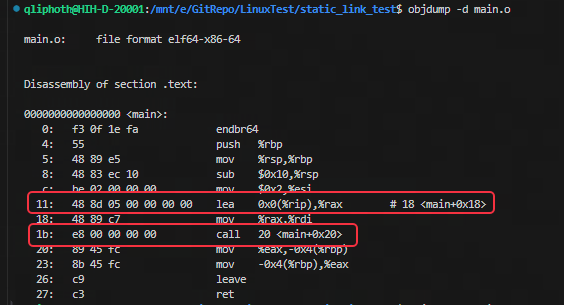
对于重定位类型 R_X86_64_32 和 R_X86_64_PC32,其重定位修正方法如下:
R_X86_64_32:属于绝对寻址方式修正,修正方式为S + A;R_X86_64_PC32: 属于相对寻址方式修正,修正方式为S + A - P。
其中,S=符号的实际地址,A=附加的修正常量,P=重定位位置的地址。对比可以看出,绝对寻址方式修正和相对寻址方式修正的区别就是绝对寻址修正后的地址是该符号的实际地址,相对寻址修正后的地址为符号距离被修正位置的地址差。
使用静态库
静态库本质上就是一组目标文件的集合,在日常开发中,我们通常都需要依赖一些基础的库,用以实现基本的输入输出、字符串操作等功能,系统将包含这些功能的目标文件打包到单独的库文件中,程序编译时可以将这些目标文件静态链接进程序中使用。在Linux中,静态库以后缀为 .a 的特殊存档文件进行存储,通常可以在标准目录 /lib/ 和 /usr/lib 中找到。
静态库的创建
1 | // add.c |
依次编译 add.c、sub.c 生成目标文件:
1 | gcc -c add.c -o add.o |
GNU binutils 工具集中提供ar命令用于将多个目标文件打包成独立的静态库文件,命令操作如下:
1 | qliphoth ~ # ar -c -r libarithmetic.a add.o sub.o |
其中:
-c选项:指定创建静态库;-r选项:指定插入目标文件到静态库中;-t选项:用于查看静态库中包含的目标文件。
这里需要注意的是,Linux下静态库文件的命名遵循一定的规范,通常是以 lib 开头,紧接着是静态库名,以 .a 为后缀名,即 lib+静态库名+.a。后续程序在引用静态库时,直接指定静态库名即可。
静态库的使用
1 | // main.c |
为了使用静态库,编译main程序时需要指定链接上面创建的静态库文件,链接器会自动从静态库中查找包含依赖符号的目标文件,并将其链入到最后的可执行文件当中:
1 | gcc main.c -L./ -larithmetic -o main |
其中:
-L选项:指定静态库的搜索路径。对于存放在系统默认搜索路径下的静态库,可以不指定;-l选项:指定需要链接的静态库名。
在链接静态库时,系统会按照特定的顺序查找静态库文件。在Linux下,默认查找的优先级顺序如下:
- 链接静态库时手动指定的搜索路径,通常使用
-L选项; - 环境变量
LIBRARY_PATH配置的路径; - 默认的静态库搜索路径
/lib、/usr/lib。

